Quantile Regression
Introduction
Given some covariates,
To demonstrate this I’ll use the LIDAR dataset from the book ‘All of Nonparametric Statistics’ 1 shown here
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import preprocessing
df = pd.read_csv(
'http://www.stat.cmu.edu/~larry/all-of-nonpar/=data/lidar.dat',
sep='\s+',
skiprows=1,
names=['range', 'logratio'],
)
df[['range', 'logratio']] = preprocessing.scale(df)
_, ax = plt.subplots(figsize=(12, 8))
ax.scatter(df.range, df.logratio)
ax.set(xlabel='range', ylabel='logratio');
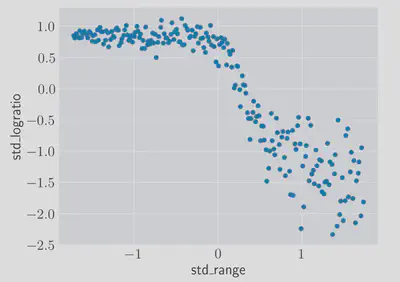
The actual meaning of the data won’t matter so much for what follows, all we need to know is that we need to predict the logratio using only the range feature. If you’re interested there is some explanatory documentation here 1.
It’s an interesting dataset displaying non-linearity as well as heteroskedasticity. We can deal with the non-linearity easily enough and just focus on predicting the central value, but what if we’re interested in producing prediction intervals for any given range value?
LAD regression
We’ll approach the problem of computing a general quantile by focusing on one, the median. Least absolute deviations (LAD) regression minimises the mean of the absolute values of the residuals:
where
While the OLS regression gives us the mean of the conditional distribution range, in the above data, effectively compressing the regression problem down to one of choosing a single correct logratio value, with no gradient.
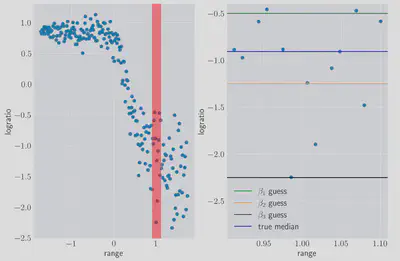
For this small region we can treat the
where the
LAD regression has a lot of interesting properties in it’s own right (as well as some cool solutions using mixed integer programming) but that is for another time. For now we’ve seen enough of an introduction to motivate the more general form.
The Pinball Loss
The ‘pinball’ loss, also known as the ‘check’ function, is defined as follows
where
so pinball is a special case of the L1 loss. It turns out other values of
For fixed range values) we want to minimise our expected loss over all the possible values of the random variable logratio). Let
where we’ve split the integral into two ranges, one for each case in the loss function. We differentiate this using Richard Feynman’s favourite trick 2 (the Leibniz integral rule):
Using this we get
where we’ve used the fact that the integral of any CDF over all values is just one and defined
Quantile Regression with Pytorch
We’ve got enough theory to get back to the example dataset. I’m going to use a simple multi-layer perceptron (MLP) neural network to perform the regression. One possible way to build this model would be to have a network output predict a quantile, and then train a model for each quantile we want. Instead, I’m going to have the last layer of the network output multiple values value, one for each quantile, and train them all in parallel. The only disadvantage of this approach is that were we to change our minds about which quantiles we’re interested in we’d have to train the whole model again.
Starting by defining the loss and the MLP using pytorch:
import torch
import torch.nn as nn
from torch.optim import Adam
def pinball_loss(quantile_predictions, target, quantiles):
pinball = lambda tau, residual: torch.max((tau - 1) * residual, tau * residual).unsqueeze(1)
losses = [
pinball(tau, target - quantile_predictions[:, i])
for i, tau in enumerate(quantiles)
]
return torch.mean(torch.sum(torch.cat(losses, dim=1), dim=1))
class QuantileModel(nn.Module):
def __init__(self, quantiles, n_hidden=32):
super().__init__()
self.model = nn.Sequential([
nn.Linear(1, n_hidden),
nn.Sigmoid(),
nn.Linear(n_hidden, n_hidden),
nn.Sigmoid(),
nn.Linear(n_hidden, quantiles.shape[0]),
])
def forward(self, x):
return self.model(x)
and then training the model using a souped-up version of stochastic gradient descent, ADAM:
import numpy as np
x = df.range.values.reshape(221, 1)
y = df.logratio.values
quantiles = np.linspace(0.05, 0.95, 10)
net = QuantileModel(quantiles, 32)
optimizer = Adam(net.parameters(), lr=0.1)
epochs = 200
losses = []
for e in range(epochs):
optimizer.zero_grad()
preds = net(torch.from_numpy(x).float())
loss = pinball_loss(preds, torch.from_numpy(y).float(), quantiles)
loss.backward()
losses.append(loss)
optimizer.step()
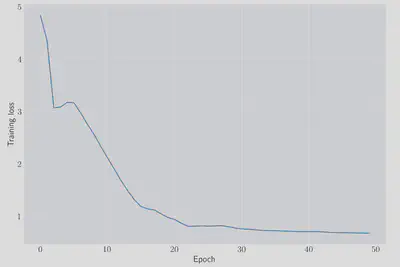
We can check that the network has managed to learn something by looking at the value of the loss function as we train:
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(losses)
ax.set(xlabel='epoch', ylabel='training loss');
and we can look at the network’s predictions for the quantiles we trained on:
fig, ax = plt.subplots(figsize=(12, 8))
xx = torch.linspace(df.range.min(), df.range.max(), 100).reshape(-1, 1)
yy = net(xx).detach().numpy()
for idx, q in enumerate(quantiles):
plt.plot(xx, yy[:, idx], 'b-', alpha=0.2)
ax.plot(x, y, 'b.')
ax.plot(xx, yy[:,5], 'r-', label='Median prediction')
fill_quantiles = lambda y0, y1, label, alpha: \
ax.fill_between(xx.reshape(-1), y0, y1, alpha=alpha, color='blue', label=label)
fill_quantiles(yy[:,2], yy[:,-3], '25%-75% region', 0.3)
fill_quantiles(yy[:,0], yy[:,-1], '5%-95% region', 0.1)
ax.set(xlabel='range', ylabel='logratio')
ax.legend();
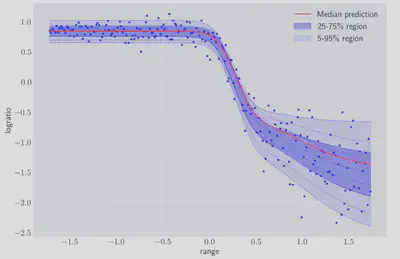
Even without tuning any of the model parameters we can see we are getting a reasonable fit. We can also look in more detail at the distribution of logratio for particular values of range:
fig, ax = plt.subplots(figsize=(12, 8), ncols=3)
min_, max_ = 1e6, -1e6
for a, range_ in zip(ax, np.array([-1.5, 0.45, 1.5])):
predictions = net(torch.from_numpy(np.array([range_])).reshape(1, -1).float()).detach().numpy().squeeze()
min_ = min(min_, predictions.min())
max_ = max(max_, predictions.max())
a.plot(
quantiles,
predictions,
marker='x',
label=f'range = {range_}',
);
ax[0].set(ylabel='logratio')
[a.set(xlabel='quantile') for a in ax]
[a.set(ylim=(min_, max_)) for a in ax]
[a.legend() for a in ax];
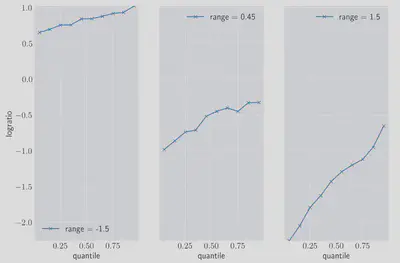
Once again we can see that not only are we capturing the change in the central value of the data, but also it’s heteroskedastic nature since the conditional distribution covers a wider range of logratio values at higher ranges.
Closing Remarks
We motivated the pinball loss by looking briefly at the LAD regression obective function, and then proved that the pinball loss can pick out whatever quantile we are interested in based on the
References
Jack Medley
Head of Research, Gambit Research
Interested in programming, data analysis, optimisation and Bayesian statistics